Making a Shell That Talks Back
The repository: https://github.com/siliconlad/aish
For the last few months, my friend Craig and I have been building aish.
As a programmer and Linux user, I spend a lot of time in my terminal. Once in a while, I want to do things in my terminal that I don’t know how to do, and this requires me to spend time looking it up.
For example, I can never remember how to compress an jpeg image.
With the capabilities of LLMs, I thought I’d try to combine the two.
After coming up with the idea, I came across ShellGPT’s shell integration feature. It does a lot of what I wanted to do, and probably a lot better as well! Still, this experience of building our own version was an amazing learning experience.
In the spirit of learning, I made some early strategic decisions:
- Write our own shell. The syntax would be based on bash, but I wanted to write our own basic scripting language. Doing this would teach us a lot, let us integrate the LLM into the shell more closely, and let us iterate quicker because we built everything ourselves.
- Use Rust. I’ve been learning Rust, and wanted to use it again. Other projects and blog posts in the same space were also using it, so it seemed like a good choice on that front too.
In this post, we’ll go through the process of creating the shell and integrating the LLM, and some decisions we made along the way.
Creating the Shell
A lot on creating a shell from scratch can be read in Josh’s blog post.
The basic architecture of the shell looks like this.
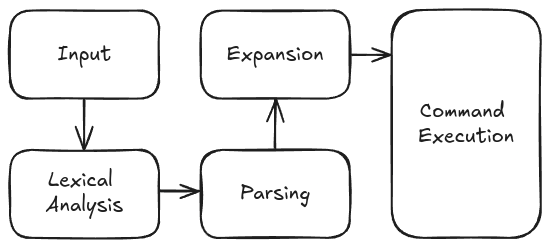
Input
This part is fairly straightforward. We have to get input from the user.
When using a normal shell like bash, you can do a lot before you hit enter. For example, you can access command history using the arrow keys, you can search your history with Ctrl + r, etc.
We use the rustyline crate to do all the input handling for us.
Lexical Analysis
My understanding of compiling techniques is limited (should’ve done it at university). So whether this is actually how lexical analysis is done is to be questioned heavily!
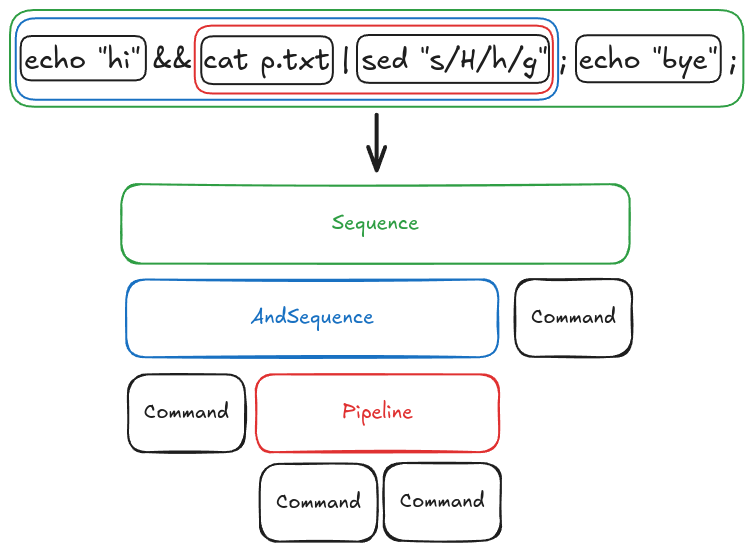
In this step, we convert the input text into a sequence of tokens. Each token type has a specific semantic meaning associated with it. For example, take the following input:
echo Hello && echo $PATH;
Our lexical analyzer will take the above string and convert it into the following sequence of tokens
Plain('echo'), Plain('Hello'), Meta('&&'), Plain('echo'), Var('$PATH'), Meta(';')
So we can see that && and ; have special meaning and have been marked as Meta tokens. Similarly, the lexical analyzer detects that $PATH is a variable and will assign the appropriate token. All the others are not special and so are assigned the generic Plain token.
What is interesting is that certain characters mean different things in different situations. In other words, the grammar for the language is not context-free. Take this example:
echo "Hello ;";
The two ; characters have different meanings. The first one, within the quotes, represents the character itself, whilst the second one has a special meaning - end of the command.
Parsing
My understanding of compiling techniques is limited (should’ve done it at university). So whether this is actually how parsing is done is to be questioned heavily!
Once we have the stream of tokens, we need to assemble them into commands that we can execute. Let’s return to the following example:
Plain('echo'), Plain('Hello'), Meta('&&'), Plain('echo'), Var('$PATH'), Meta(';')
The parser will construct commands from the stream of tokens.
To do this, it consumes tokens until we hit a Meta token. We assume that the command name is the first token and the following tokens are its arguments. In the example, the command name would be echo and the argument is Hello.
After that, we would look for any redirection modifiers by checking if the next token is one of the three redirection meta characters: >, <, >>.
In the example, the next token is &&, which indicates we are creating a specific sequence of commands (AndSequence). So all subsequent commands until we reach a meta character with higher precedence (like ;) will be added to this AndSequence container.
There are three types of sequence containers:
Sequencecreated by;AndSequencecreated by&&Pipelinecreated by|
In this way, we consume the stream of tokens and construct commands and then sequences of those commands based on the meta characters separating them (and sequences of sequences and so on).
Note that the meta characters have a precedence.
Sequencecan containAndSequence,Pipeline, and commands.AndSequencecan containPipelineand commands.Pipelinecan only contain commands.
Expansion
Just before we run each command, we perform expansion.
For example, all Variable tokens are expanded to their values.
Note that when implementing this, we needed to evaluate variables last-minute. For example, imagine you have the following input:
> export FOO=BAR && echo $FOO
The expected output is BAR, but for this to work, you need to expand the Variable(FOO) token only after the first command export FOO=BAR has executed.
Command Execution
The last step is to execute the command. How you do this depends on what command is being executed. Most commands will be external commands, that is commands on $PATH.
GNU core utilities has a huge number of executables that you are probably familiar with (e.g. grep) that come standard with most Linux distros. To run these commands, you create a child process that runs the executable with the correct arguments.
However, not all commands can be run like this. The obvious one being cd. cd changes the current working directory of current process. Because of this, you cannot spawn a new process to run cd like you can with other commands! You need cd to run in the same process that’s running the shell, otherwise it will take no effect. cd is therefore a special command within the shell, called a builtin, when executed does not spawn a new process. Bash has a number of builtins.
The exception is when builtins are being run within a pipe. Try this:
> cd ~/Documents | echo "hello"
> pwd
Assuming you weren’t already in ~/Documents you’ll notice cd had no effect!
The LLM Part
Once we have the shell, the next part is to integrate the LLM.
To make things easy, we used the OpenAI API. It would be cool to explore how we can use local models instead, but that’s more involved and so we spare that for a future post.
Use Cases
Let’s list some situations in which a user might want to use the LLM within their shell. A lot of this is inspired by ShellGPT, so props!
Prompt it directly
It would be nice to directly ask the LLM a question.
> What OS am I using?
LLMs in Pipelines
Using an LLM within a pipeline has huge potential.
> echo "Hello" | Translate to French
Bonjour
Output Redirection (>)
Note that for both cases above, we would also like to redirect the outputs into a file using the > operator. For example, we might want the LLM response to “What OS am I using” to be written to file.txt.
> What OS am I using? > file.txt
Detecting LLM Prompts
The challenge was to detect when a string was a prompt for the LLM and when it was a normal shell command. We wanted something that was intuitive and natural.
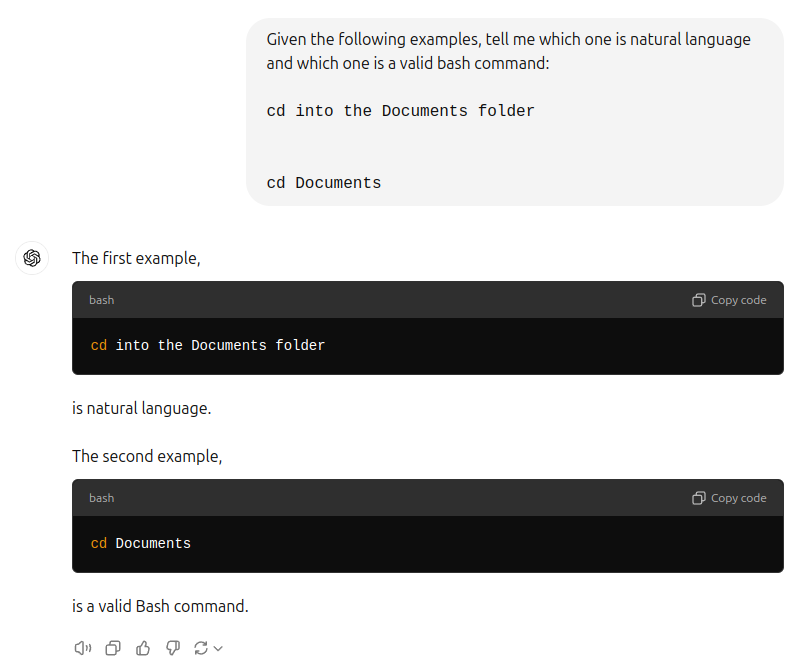
The main challenge is illustrated in the following example:
> cd into the Documents folder
> cd Documents
The first example is clearly a prompt, while the second is a valid command. Both start with a valid shell command: cd. What is the best way to distinguish between the two cases?
Get the LLM to Decide
Perhaps we can get the LLM to distinguish between the two cases.
A major problem with this approach is that every command entered into the shell will have to go through the LLM. This increases latency and costs unnecessarily. We can do better.
LLM Failover
Perhaps we could treat all inputs as a bash command. If the command fails, we should send it to the LLM instead. This is better because it limits the number of times we call the LLM.
However, to me, this feels a bit reckless and limits the user’s ability to decide when to use the LLM. I think we can do better.
Using Quotations
The best idea we came up with was to surround prompts in quotes. We can then identify prompts by looking for isolated text within quotation marks. By isolated, we mean not an argument for another command:
> echo "Hello" # Not isolated
> "Hello" # Isolated
> cat prompt.txt | echo "Summarize" # Not isolated
> cat prompt.txt | "Summarize" # Isolated
In essence, the quotation marks is the command. This also allows us to do output redirects which would be difficult to implement in the other two situations.
> echo "Tell me a joke" > joke.txt # Not isolated
> "Tell me a joke" > joke.txt # Isolated
The llm Builtin Command
There is an additional use case we didn’t mention above.
> llm < prompt.txt
Here, the prompt is stored in a file, and we want to use the contents of the file as the prompt to the LLM. You can imagine this would be necessary for more complicated prompts.
We created an llm builtin command (like cd is) to handle this situation.
Conclusion
Working on this project was an awesome learning experience.
Parsing statements following the bash syntax was a challenge and an iterative process where each new feature added more and more complexity. Not having done compiling techniques at university, I found this a bit of a challenge. Definitely something I want to learn more about!
Making design decisions on how to integrate the LLM was also interesting and coming up with different ways and comparing them was a lot of fun.
There’s a lot more we could do with this project.
- Using local models to improve privacy and latency.
- More shell features to make the shell itself more useful.
- A whole agentic workflow could be implemented behind the scenes to improve and extend its capabilities.
Working on this project has made me excited about the potential of LLMs in making applications more intelligent. I imagine applications that can learn your tastes and workflows and help you become more productive.
A lot more work is needed to to make this a reality, but I’m optimistic.
Onwards!
References
Some useful references we found: